Naive analysis of books
March, 2016
I have 65.000 books from Project Gutenberg
![]()
![]()
![]()
Create two helper functions
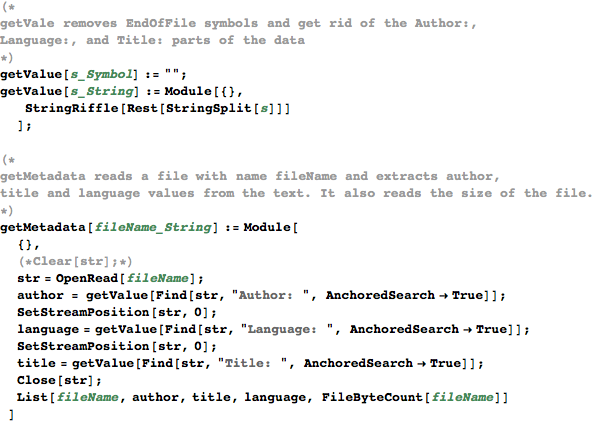
How much RAM does that data use
![]()
![]()
Let’s try to read some metadata from 10 books
![]()
![]()

The same metadata in tabular form
![]()
| 10000.txt | Anonymous | The Magna Carta | English | 101718 |
| 10001.txt | Lucius Seneca | Apocolocyntosis | English | 52510 |
| 10002-8.txt | William Hope Hodgson | The House on the Borderland | English | 306901 |
| 10002.txt | William Hope Hodgson | The House on the Borderland | English | 306892 |
| 10003-8.txt | Mary King Waddington | My First Years As A Frenchwoman, 1876-1879 | English | 380829 |
| 10003.txt | Mary King Waddington | My First Years As A Frenchwoman, 1876-1879 | English | 380817 |
| 10004-8.txt | Lindsay, Anna Robertson Brown | The Warriors | English | 302753 |
| 10004.txt | Lindsay, Anna Robertson Brown | The Warriors | English | 302750 |
| 10005-8.txt | George Tucker | A Voyage to the Moon | English | 434769 |
| 10005.txt | George Tucker | A Voyage to the Moon | English | 434760 |
Get the metadata from all 65.000 books
![]()
How longc did it take to get the four metadata values from those books?
![]()
![]()
![]()
![]()
![]()
![]()
Now it’s time to select the training sets and the validation sets. First select all Shakespeare, Jules Verne, and some other author to be decided.
Still, first we will ignore anything that’s not written in English.
Which languages do we have?
![]()
| English |
| English and Aleutian |
| French |
| Latin |
| German |
| Italian |
| Dutch |
| Swedish |
| Danish |
| Spanish |
| Finnish |
| French (with English) |
| Bulgarian |
| Spanish and English |
| English and Spanish |
| Serbian |
| Norwegian |
| Portuguese |
| German and Catalan |
| Esperanto |
| French and Dutch |
| English / French |
| Romanian |
| FASTA |
| English and French |
| german |
| (English and Nahuatl) |
| English with French |
| English, with Italian and French |
| Chinese |
| Spanish with English |
| French/English |
| French and English |
| English, Latin, Spanish, and Italian |
| English with Khasi (Language spoken in N.E. India) |
| Czech |
| Tagalog |
| ASCII |
| English and Latin |
| ***CAREFUL*** |
| Dutch and Flemish |
| Portugese |
| French / English |
| Spanish/English |
| Welsh |
| Italian and English |
| English and Old English |
| English, Middle (1100-1500) |
| english |
| en |
| Russian |
| EN |
| Catalan |
| Latin and English |
| Latin with English and Greek (ancient) |
| English and Nahuatl |
| Icelandic |
| Polish |
| En |
| Quiche |
| French / Onondaga / English |
| Spanish and Tagalog |
| Ilocano |
| Iloko |
| English and Chinook |
| Interlingua |
| Irish |
| Iloko, Spanish |
| Friulian |
| Afrikaans |
| English/latin |
| Kamilaroi and English |
| Gascon |
| Greek |
| Italian and French |
| Neapolitan |
| Hebrew |
| Hungarian |
| Japanese |
| Frisian |
| Venetian |
| English - Latin |
| Spanish, English and Tagalog |
| Cebuano |
| Galician |
| Nahuatl |
| Maori |
| Middle English |
| German and English |
| Breton |
| Arapaho |
| Czech, Esperanto |
| Zh |
| Inuktitut |
| Bagobo |
| Kashubian and Polish |
| Gaelic |
| English and German |
| Portuguese & French |
| GR |
| Slovenian |
| NU |
| Englishs |
| Telugu |
| JP |
| English & Spanish |
| Ojibwa |
| Chinese and English |
| French and Latin |
| Arabic |
| Estonian |
| Farsi |
| 48771 |
| Scots |
| 5648 |
| Latin, German |
| GERMAN |
| English/Latin |
| German, with English comments |
How many different languages?
![]()
![]()
Well, drop everything not in English and only English

![]()
|
|
Now from the set, select texts written by Shakespeare, but first create a small utility function
![]()
![]()

![]()
![]()
Select all works by Jules Verne
![]()

![]()
![]()
Now, who should the third author be? Which authors do we have to choose from?
![]()
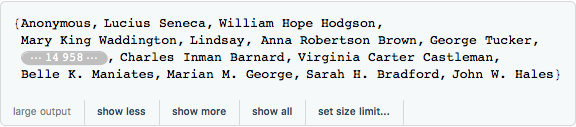
![]()
![]()
Ah, that’s a lot! That numbers gives one the urge to examine the author to works per author relationship, but that’s not my mission here.
Maybe go for Dosteyevsky?
![]()
![]()
Naw, too many different spellings. I’ll select Victor Hugo as the third author
![]()

Now, onwards to the stuf I know nothing about, but which is so easy to do in Mathematica. First create a function that splits a list of works into a training and test set

Then create training and test sets for the three authors
![]()

![]()
![]()
![]()
Now it’s time to actually load the content of the books or works into memory
![]()
And create a classifier function based on this content

![]()
That took less than a minute!
Now let’s test the classifier
![]()
![]()

![]()

![]()
![]()
To my laymen’s eyes it looks good. Let’s pick a “random” book
![]()
![]()
Of pur three authors, who did most likely write that text?
![]()
![]()
I don’t know…
![]()
![]()
Why is that more Shakespeare than Verne?
What if I wrote som small sentences where I tried to sound like one of the three authors?
![]()
![]()
![]()
![]()
![]()
![]()
Below just some jibberish…
![]()

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
An option for showing the timing for the latest computation
![]()
![]()